|
|
Det finns många olika datorprogram som kan användas för att underlätta beräkningar av variansanalys. På kursen fungerar även programspråket R som ett komplement till Excel. Du får en bra start för att lära dig använda R i de två första kapitlen på webbsidan Evolutionary Genetics: Concepts, Analysis & Practice och på kursen kommer vi att hänvisa till paketet GAD: Analysis of variance from general principles. Se också de genomarbetade exempel, som finns länkade till i läshjälperna för de olika avsnitten. Excel är smidigt att använda för enklare analyser, som t.ex. ANOVA med 2 faktorer. För att underlätta användandet följer nedan ett exempel som illustrerar hur det går till. Utseendet på menyer och fönster varierar lite beroende på om du använder Mac eller Windows och om du använder en svensk eller engelsk version, men du kommer nog att känna igen dig ändå!
Du kan även se beräkningarna i Excel-filen ANOVA2xl.xlsx.
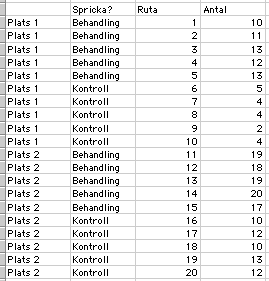
Tänk dig att du har gjort ett experiment där du vill testa modellen att förekomsten av sprickor i berget på exponerade lokaler orsakar lokalt högre täthet av strandsnäckor. Du föreslår således hypotesen att om du gör nya sprickor i berget (med huggmejsel!) kommer dessa ytor att ha fler snäckor efter tre månader än ytor där inga sprickor görs (kallade kontroller)! Tänk dig vidare att du gör experimentet på två platser och att du efter tre månader får resultatet som visas nedan (Fig. 1)
Experimentet är utformat som en två-faktors ANOVA där faktorn "Plats" är slumpad (nivåerna är slumpmässigt valda för att representera "klippstränder") och "Spricka?" är en fixerad faktor (med nivåer som är specificerade av hypotesen). Dessutom finns det möjlighet att testa om effekten av sprickan är samma på båda platserna, d.v.s. om det finns en interaktion. För att man ska kunna göra analysen i Excel krävs det att data är organiserade på ett speciellt sätt (Fig. 2).

När detta är gjort kan man utföra sin ANOVA. Detta görs med analysverktyget som du kan hitta i verktygsmenyn (Fig. 3)…
…får du fram följande fönster (Fig. 4 och 5). Kan du inte hitta dataanalys kanske du behöver installera det!
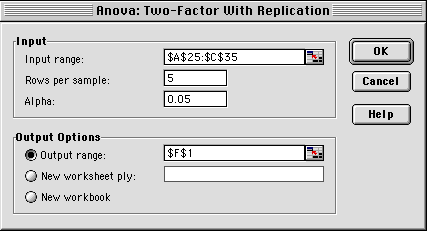
Nu har du kommit till fönstret där du skall specificera villkoren för ditt test (Fig. 5). Sätt markören i den översta tomma rutan för att specificera indata… (Fig. 6)…

Skriv in antalet replikat per behandling och plats (här n = 5) och den önskade risken för typ 1 fel (vanligtvis 0,05). Ange sedan var du vill att resultaten skall visas. Oftast är det bra att ha resultaten på samma sida. Pricka därför i "Utdataområde" och sätt markören på en ruta där du vill att resultaten skall börja. När du gjort detta bör fönstret se ut som i figur 7 och du kan klicka OK och vips är din ANOVA nästan klar!
Resultatet av analysen visas i nedre delen av figur 8.
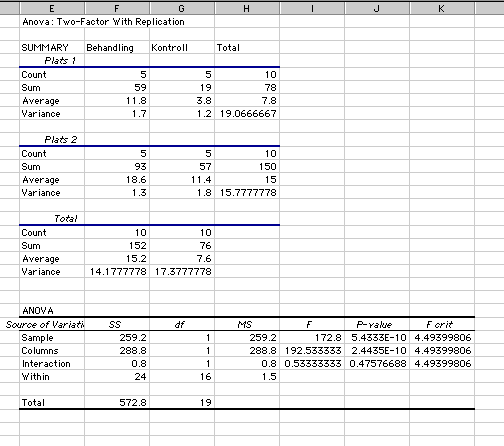
Några VIKTIGA steg återstår dock! Tabellen visar korrekt SS, MS och df för "Plats" (Sample), "Spricka?" (Column) och interaktionen, men eftersom ANOVAN i Excel alltid antar att faktorerna är fixerade kommer de F-kvoter och p-värden som beräknas för huvudfaktorerna endast att stämma om du bara har fixerade faktorer (se Underwood, 1997; Tabell 10.8 s. 328). För att i detta fall utföra en korrekt analys måste du alltså bilda nya F-kvoter och räkna ut nya p-värden.
Börja med att testa om det finns en signifikant interaktion. Detta test är korrekt utfört i tabellen eftersom interaktionen alltid skall testas över residualen.
(a) Om interaktionen är signifikant - ANOVAN är färdig. Gör a posteriori-test på interaktionen (se stycke 10.8).
(b) Om interaktionen har ett 0.05 < p < 0.25 - bilda en F - kvot för den fixerade faktorn med MS för interaktionen i nämnaren. Testet för den slumpade faktorn gäller enligt tabellen (Fig. 8). Testa sedan den fixerade faktorn genom att räkna ut p-värdet med hjälp av funktionen "F.FÖRD.RT".
(c) Om interaktionen har ett p > 0.25 (som i exemplet ovan), testa huvudfaktorerna med en sammanslagen MS i nämnaren (Fig. 9). Summera direkt i Excel SS för interaktionen och residual (i Excel kallad "Within"). Gör likadant för df och räkna ut ett nytt ("poolat") MS. Räkna sedan också ut F och p direkt i Excel (Fig. 9).

Experiment med en nestad faktor. Som du lagt märke till gäller ovanstående exempel ett fall när experimentets faktorer är ortogonala, d.v.s. båda behandlingarna (spricka och ingen spricka) finns replikerade på båda platser. För att utföra ANOVA i ett experiment där en faktor är nestad i en annan behövs andra beräkningar. Som ett exempel kan du tänka dig att experimentet istället varit utformat så att endast en typ av behandling fanns på vaje plats. Det fanns alltså två platser med fem vardera konstgjorda sprickor och två platser med fem kontrollrutor på vardera plats. Detta hade inneburit att "Plats" var nestad i faktorn "Spricka?".
Tyvärr finns inte något analysverktyg i Excel där man direkt kan beräkna en nestad ANOVA. Däremot kan man använda ovanstående procedur för att beräkna SS och df för att utföra en nestad analys. För att göra detta "låtsas" man att experimentet är utformat med ortogonala faktorer och beräknar df och SS som i Fig. 8.
Räkna sedan ut df och SS för den nestade faktorn, "Plats(Spricka?)", genom att summera värdena för faktorn Plats (i tabellen kallad "Sample") och den påhittade interaktionen (Fig. 10). Beräkna sedan MS och bilda F enligt de principer som du lärde dig i kapitel 9. F-test gör du med funktionen "F.FÖRD.RT" i Excel.

|
|
Senast ändrad: 28 november
2000
Av: carl.andre@tmbl.gu.se och
mats.lindegarth@tmbl.gu.se